
The 60-year-old code behind $5 trillion in healthcare
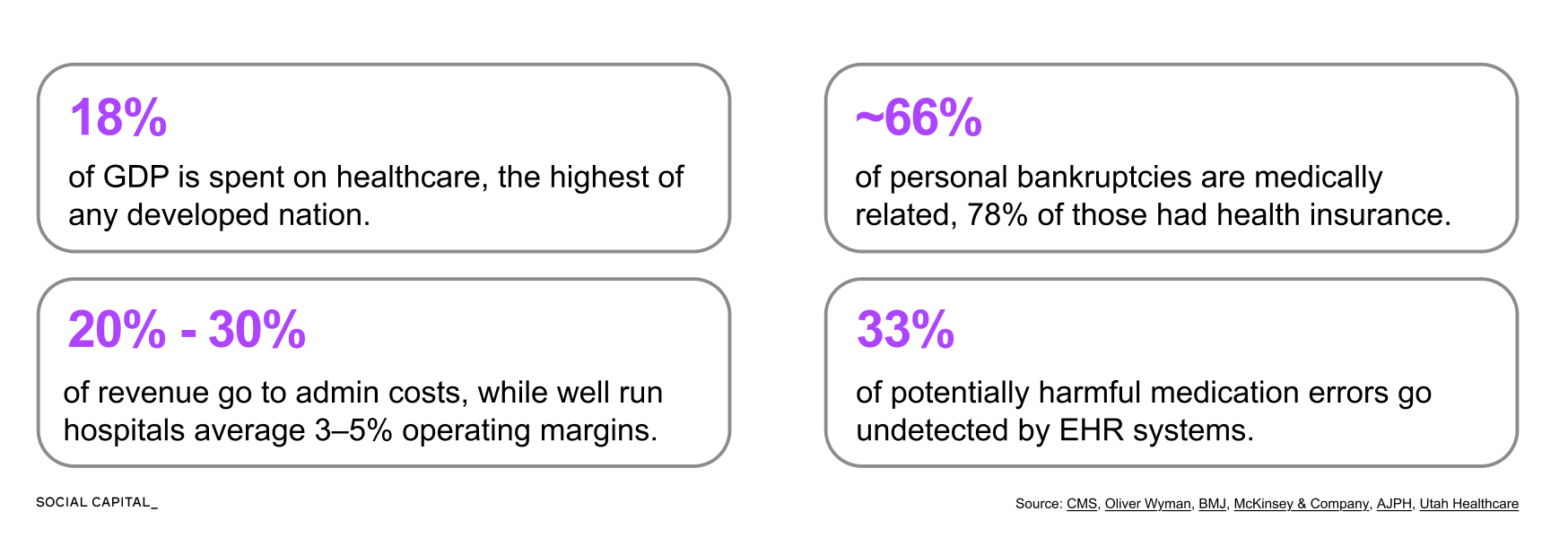
The U.S. spends $5.3T a year on healthcare, yet patient medical records are often fragmented across more than 10 disconnected systems. Its core architecture has...
In February 2024, a ransomware attack on Change Healthcare shut down claims processing for roughly 40% of U.S. medical claims.
The breach cost over $2.45B and exposed medical information of 192.7M Americans, with 94% of hospitals reporting financial damage.
BlackCat (ALPHV) ransomware group accessed the system through a basic vulnerability:
The portal lacked multi-factor authentication.
While a criminal organization reached the records of 6 in 10 Americans through a single external access portal, the healthcare system itself still cannot move those records between two hospitals.
Up to 50% of patient records fail to match correctly when exchanged between systems. When a doctor treats a patient, information stored in another hospital’s system remains invisible at the point of care.
To understand how the system works and why it behaves this way, our Social Capital research team did a deep dive and examined the sector from first principles.
What emerged was a system held in place by three structural layers, each reinforcing the others, starting with a decision that has constrained progress in healthcare information for 60 years.
The 1966 Decision

In 1966, Massachusetts General Hospital needed a computer system that could serve 20 departments simultaneously without ever crashing during patient care. The available hardware was a PDP-7 with 4KB of RAM.
Three developers built a system called MUMPS that fused an operating system, a programming language, and a database into a single inseparable layer.
That fusion solved a critical problem: dozens of departments writing to the same patient record at the same time without conflicts or crashes.
It also created the constraint that still shapes most Electronic Health Record (EHR) systems today: because the layers were fused together, migrating away means replacing the entire system at once.
MUMPS was optimized to answer one question: what is happening with this patient right now?
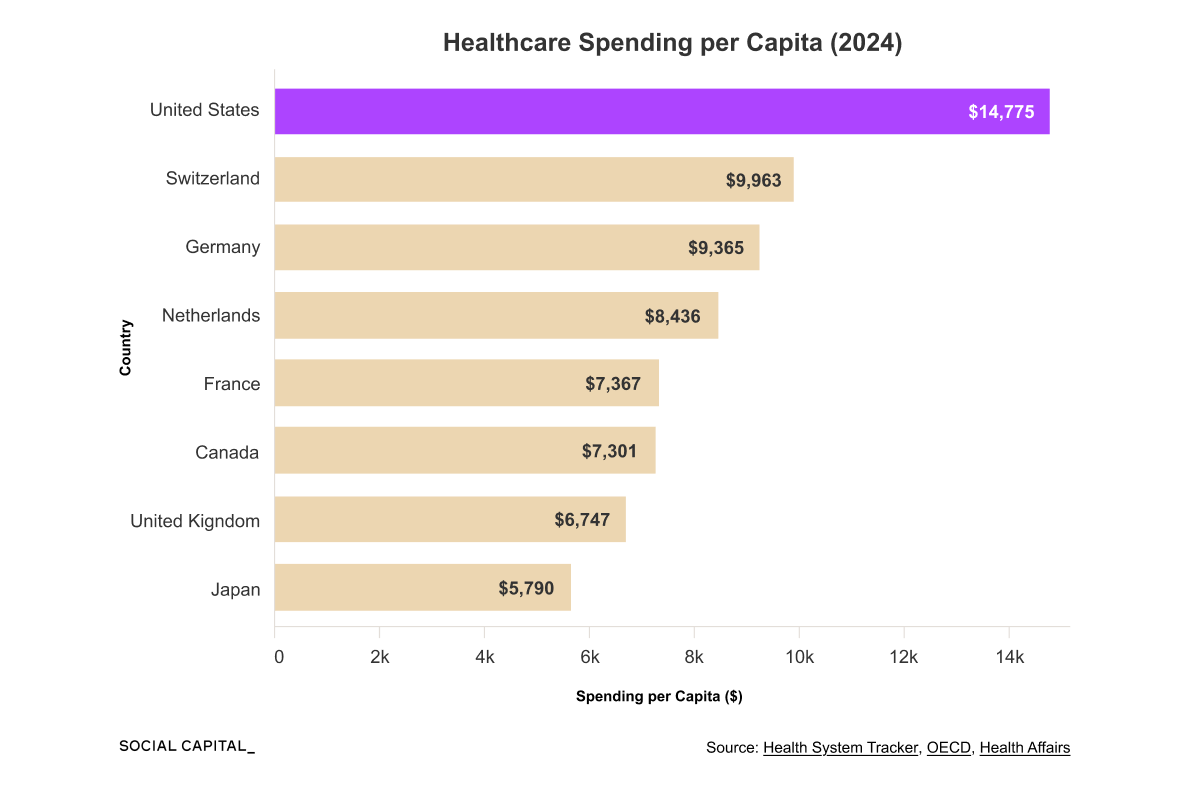
Healthcare spending has grown from 6.9% of U.S. GDP in 1970 to 17.6% by 2024, and the questions EHR systems need to answer today are fundamentally different.
Payers want to know which treatments work and which providers are expensive.
Regulators want to measure quality metrics like infection and readmission rates.
Researchers want to identify at-risk patients across entire populations.
These questions require data to move across patients, providers, and systems.
The existing architecture was not designed to move data cleanly across systems, so translation work shifted to humans and intermediary processes.
The $1 Trillion Administrative Layer
The U.S. spends roughly $1 trillion each year on healthcare administration, representing 25 to 30% of total healthcare spending and about 3.5x as much per capita as Canada.
That spending funds a massive translation workforce, including roughly 185,000 medical coders who convert clinical language into billing codes across more than 70,000 diagnosis codes and 10,000 procedure codes.
The administrative layer exists because each insurer maintains its own rules, contracts, and approval processes, requiring this translation to happen repeatedly across fragmented payers and providers.
In an economy where automation and AI are increasing efficiency across nearly every sector, why has healthcare resisted?
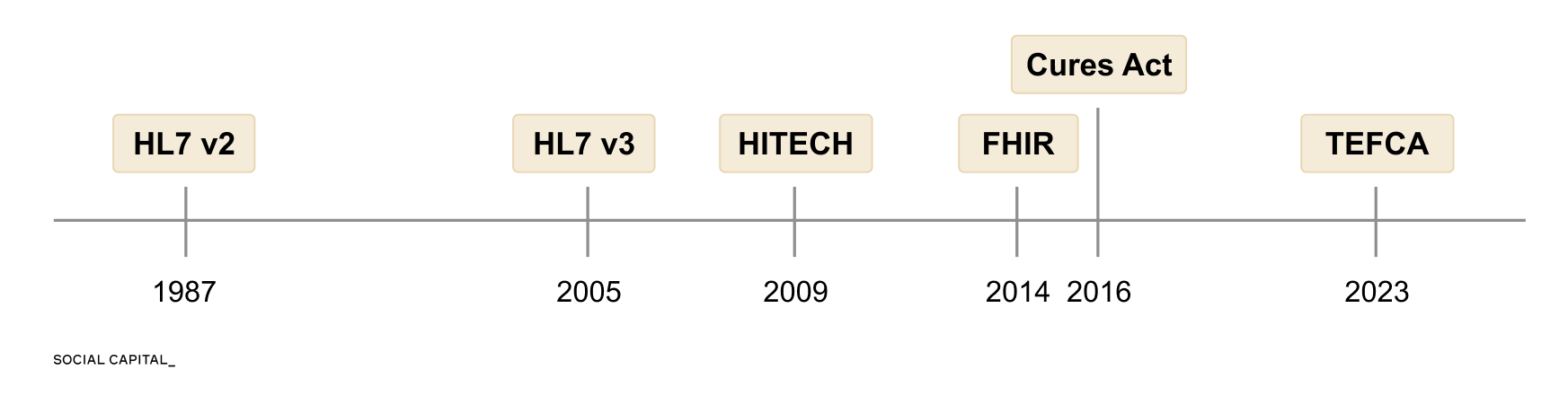
40 Years of Failed Interoperability
Getting different EHR systems to share patient data requires four things to happen:
Systems must be able to connect.
Data must be formatted consistently.
Systems must interpret what the data means.
Governance and consent must permit exchange.
Over the past four decades, there have been 6 major attempts to solve these issues.
Each one made progress, but none solved all four.
Consolidation Emerges
As a means to address both interoperability and complexity, market participants began to acquire more of the system.
Epic consolidated horizontally, capturing 42% of the hospital EHR market overall and approaching 70% among hospitals with 500 or more beds.
UnitedHealth consolidated vertically, capturing multiple layers of the healthcare system. It insures 52M lives through UnitedHealthcare, employs over 90,000 physicians through Optum Health, manages pharmacy benefits through OptumRx, and processes 40% of all U.S. claims through Change Healthcare.
This shifted coordination from across organizations to within them, but the core structural constraints remain.
Can LLMs Fix U.S. Healthcare?
The constraints described above emerge from three layers, each reinforcing how data moves, how it is used, and who captures value.
Across all three layers, a common limitation appears: the system depends on data that is fragmented, inconsistently structured, and difficult to interpret at scale.
Even today, most AI systems in healthcare focus on imaging rather than processing unstructured clinical language.
However, recent LLMs introduce a new capability: they can interpret clinical language at scale in ways previous systems could not, without requiring a rebuild of the underlying architecture.
Two parallel efforts are now emerging. AI is being integrated into healthcare institutions, while new tools allow patients to access and use their own data directly.
In January 2026, OpenAI and Anthropic launched healthcare products within days of each other at the J.P. Morgan Healthcare Conference, signaling how quickly both sides of this dynamic are developing.
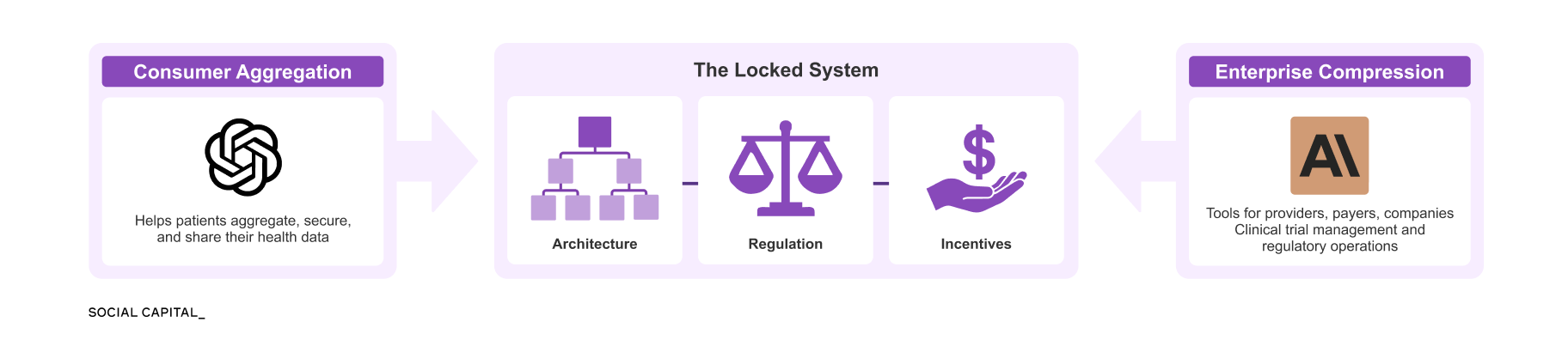
Together, these forces apply pressure on the system from opposite directions.
Learn With Me
Previous reforms either required the underlying architecture to be rebuilt, vendors to cooperate, or institutions to share data on new terms. LLMs create a new possibility for change by enabling the interpretation of unstructured clinical language on top of the existing infrastructure. This is a major distinction, and it makes this sector worth studying now.
I had our research team at Social Capital explore the current constraints in Healthcare IT and innovation potential. In the Deep Dive, you’ll learn:
How did a programming language built on 4KB of RAM become the foundation for systems managing 300M+ patient records, and why has no one been able to replace it?
What does Epic’s proprietary data dictionary control, and why can a hospital export its own data but not read it?
How did the Change Healthcare breach expose 6 in 10 Americans, and what does its structure reveal about the concentration risks in U.S. healthcare infrastructure?
Why do 81.7% of prior authorization denials get overturned on appeal, and what does that reversal rate suggest about the system’s actual function?
Which countries achieved full health data interoperability before the U.S. even digitized, and why can’t the U.S. replicate their approach?
How are LLMs already being deployed in clinical trial matching, ambient documentation, and automated coding, and where are the limits?

This is the first part of a two-part series. Part Two will cover the race between platform companies and incumbents, the regulatory frameworks taking shape around clinical AI, the capital flowing into AI-native healthcare infrastructure, and whether the system absorbs this capability the way it absorbed every previous reform.
If you want to learn more with me, sign up below to read the full Deep Dive (and all our past releases).
Chamath
Disclaimer: The views and opinions expressed above are current as of the date of this document and are subject to change without notice. Materials referenced above will be provided for educational purposes only. None of the above will include investment advice, a recommendation or an offer to sell, or a solicitation of an offer to buy, any securities or investment products.
Deep Dive PDF below ↓